A beta version of Voice Input is provided for early access to this new DataWedge feature. Zebra welcomes feedback at the Developer Portal's DataWedge Forum.
Overview
Voice Input enables DataWedge to convert spoken entries into keystrokes as if they were typed or acquired from a scan. Voice Input uses the Google speech recognition engine included on GMS devices. Voice-to-data capture can be useful in cases when a barcode is wet, damaged, covered with stray markings or otherwise cannot be scanned.
Voice Input options:
- Begin voice capture with a defined start phrase
- Terminate voice capture with a phrase or timeout value
- Send a TAB character when speaking the "send tab" command
- Send an ENTER character when speaking the "send enter" command
- Limit returned data to alpha or numeric characters
- Play an audio prompt when waiting for a start phrase or data capture
- Validate spoken data, edit acquired data as needed
- Works offline
This feature is supported only on Zebra GMS devices with Android Nougat and later.
Watch the DevTalk presentation on DataWedge Voice Input:
How it Works
Voice Input relies on DataWedge profiles for configuration. Ensure that the application to receive the voice captured data is associated to the profile. The Voice Input section in the profile provides the options that control the voice data capture. See Main Features section below.
When running, Voice Input is placed in the state "waiting for start phrase" (see Figure 8). Voice data capture begins after speaking the predefined "start phrase", which then changes the state to "waiting for data" (see Figure 9). Voice capture stops automatically after speaking the data or after speaking an optional "end phrase", if defined. The data source can be identified as voice input to process the voice data according to any application requirements. Barcode scanning and voice input can exist in the same DataWedge profile so both data capture methods may be used interchangeably.
Watch a demo on the basics of Voice Input with DWDemo app:
Watch a demo showcasing the Send Enter command for multiple field entries:
Main Features
Voice Input features are accessible from the DataWege profile.
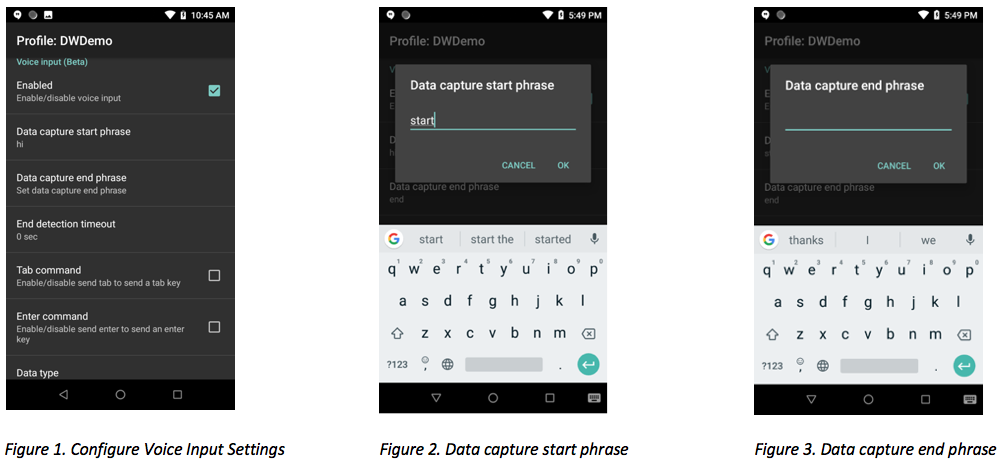
Enabled - Enables voice input. See Figure 1.
Data capture start phrase - Required phrase to start the data capture. The default value is "start." Numbers and special characters are not supported as part of the start phrase. See Figure 1 and 2.
Data capture end phrase - Optional phrase that ends the data capture. There is no default value. See Figures 1 and 3.
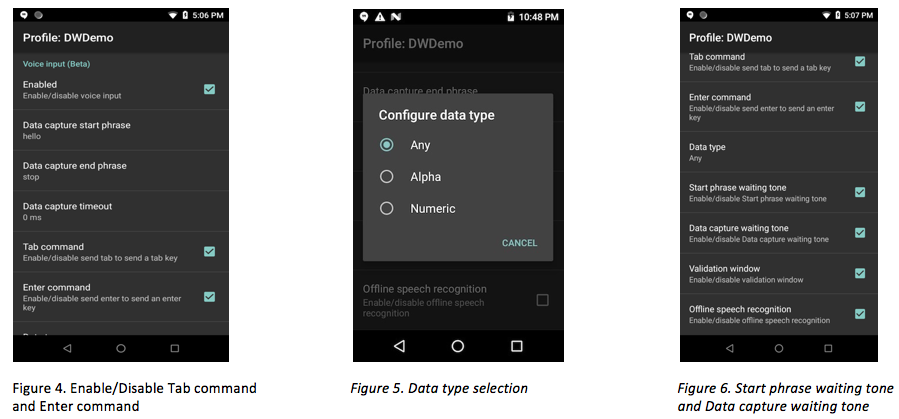
Tab command - Sends a tab key when speaking the command "send tab". This command is supported only when the device is at the "waiting for start phrase" state. See Figure 4.
Enter command - Sends an enter key when speaking the command "send enter." This command is supported only when the device is at the "waiting for start phrase" state. See Figure 4.
Data type - Configures the data type to be returned, with selections of: Any, Alpha, or Numeric. The data type is required to restrict data captured according to the preferences. See Figure 5. Data type selections:
- Any - All scanned data is returned. For example, if the barcode ABC123 is scanned, it will return ABC123 as is.
- Alpha - Only alpha characters are returned. For example, if the barcode ABC123 is scanned, it will return ABC only.
- Numeric - Only digits are returned. For example, if the barcode ABC123 is scanned, it will return 123 only.
Start phrase waiting tone - Controls the start phrase waiting tone. It enables/disables the audio feedback for “waiting for start”, notifying that the device is waiting to start the speech engine in case the toast message notification is missed and there is a change in “waiting for data” state. See Figure 6.
Data capture waiting tone - Controls the data capture waiting tone. It enables/disables audio feedback for “waiting for data”, notifying that the device is waiting to capture data in case the toast message notification is missed. See Figure 6.
Offline speech recognition - Enables offline speech recognition when there is no access to the internet. This uses an offline recognition speech engine to detect the data spoken. See Figure 6.
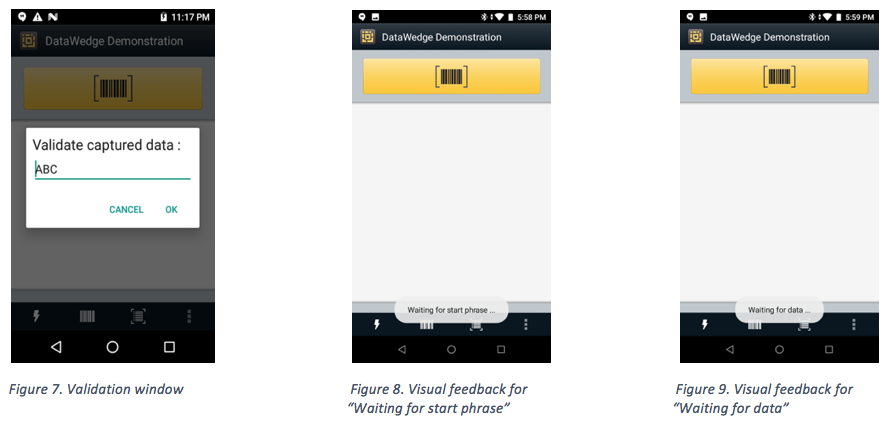
- Validation window - Validates the result after speaking, displaying the spoken data and provides for editing the data on the same screen, if needed. This is useful in offline mode, since the results received in this mode might not be accurate. See Figure 7.
See Limitations below.
Configuration
Voice Input Parameters
DataWedge Voice Input can be controlled programmatically with DataWedge APIs. Refer to DataWedge Voice Input Plugin in Set Config API to configure the following Voice Input parameters:
| Param Name | Param Values |
|---|---|
| voice_input_enabled | true, false |
| voice_data_capture_start_phrase | start (default value) |
| voice_data_capture_end_phrase | [blank] (default value) |
| voice_tab_command | true, false |
| voice_enter_command | true, false |
| voice_data_type | 0 - Any, 1 - Alpha, 2 - Numeric |
| voice_start_phrase_waiting_tone | true, false |
| voice_data_capture_waiting_tone | true, false |
| voice_validation_window | true, false |
| voice_data_capture_waiting_tone | true, false |
| voice_offline_speech | true, false |
Set Voice Input Configuration Sample
Refer to DataWedge Set Config API.
Limitations
- Voice Input is validated only with English. For use with other languages, the device must be connected to the internet.
- Offline speech recognition provides lower accuracy levels.
- In GMS Restricted mode with the use of App Manager's DisableGMSApps action, Voice Input will not work since it relies on Google speech recognition.
- Do not use Google Assistant while DataWedge Voice Input is in use, as it can lead to undesirable behavior.
- Providing numbers and other special characters as part of the data capture start phrase is not supported.
- Voice Input is not supported if Enterprise Home Screen (EHS) is in restricted mode. However, enabling all the privilege settings in EHS will reinstate Voice Input in DataWedge.
Related guides: